Актуальный скрипт парсинга яндекс wordstat. Парсер ключевых слов. Тестирование парсера Wordstat
Самое первое, что потребуется выяснить: что такое парсить. Возможно, Вы знаете это определение, а даже если и нет, понять будет легко. Парсить (Parsing) – значит собирать информацию из какого-либо источника с последующей обработкой данных. Если говорить о частных случаях, парсинг в seo (по-другому парсинг поисковой выдачи) – это сбор и анализ статистики запросов пользователей.
Поисковые системы тоже используют парсинг. Так, поисковые роботы парсят, анализируя веб-страницы и занося информацию о них в базу данных поисковиков.
Яндекс.Вордстат – сервис очень полезный в seo. Но работать с ним возможно только при наличии аккаунта Яндекс. Он позволяет подбирать ключевые слова на основе запросов пользователей, чтобы далее составить из них семантическое ядро.
Первым делом, необходимо определить тематику. Что Вы продаете? Какие услуги Вы предоставляете? Определив свою тематику и что будете запрашивать, можно начинать пользоваться Вордстат.
В строку поиска вводите свой запрос. И расширяете его с помощью выданных результатов.
Результаты формируются в две колонки. Цифра рядом с запросом – прогнозируемое количество показов в месяц, которое можно получить, выбрав понравившийся запрос ключевой фразой. Прогноз идет за последние 30 дней до даты обновления статистики.
Можно настроить, чтобы выдача показывалась по регионам. Если Вы предоставляете услуги только в Москве, выберите вкладку «Все регионы» (она находится чуть ниже поисковой строки) и настройте под себя.
В левой колонке все фразы со словами Вашего запроса, и слова в ней отсортированы по убыванию частоты показов. Вам важно сразу выделить те варианты расширенных ключей, которые будут являться для вашего проекта целевыми. Целевые - это те запросы, по которым пользователь, вводящий запрос в поисковую систему, может найти нужное ему на Вашем сайте. Целевые фразы будут более низкочастотными, и пользователи, пришедшие по ним с выдачи, смогут найти то, что хотели, а значит не покинут Ваш сайт сразу. Вам важны эти посетители, ведь именно они могут совершить целевое действие – купить товар или заказать услугу.
Проверьте выбранные фразы – исключите те, у которых частотность близка к нулю. Для этого используйте оператор “ “ (Кавычки).

После чего переходите к правой колонке.
В правой колонке показываются запросы, похожие на Ваши. Собрав нужное, не забудьте проверить фразы оператором “ “ (Кавычки).

Набрав достаточное количество ключевых фраз, Вы приступаете к следующему этапу: делите фразы по частотности. На этом Ваша работа с Вордстатом завершена.
По некоторым ключевым словам Вордстат выдает неправильную информацию. Как же ее проверить? Перейдите на вкладку «История запросов» и обратите внимание на статистику.
Показания статистики представлены в 2-х графиках: абсолютное и относительное.

Абсолютный показатель – это фактическое значение показов в разные периоды времени. А относительный показатель – это отношение показов по интересующему запросу к общему числу показов в сети. Он демонстрирует популярность запроса среди всех других.
Если график относительного значения выше абсолютного, то, может быть, идет автоматическая накрутка запроса, или интерес к запросу выше нормы. Возможно, это связано с сезоном. Так спрос на лыжи выше зимой.
Процесс парсинга можно автоматизировать. В этом случае возможно использование не только платных и бесплатных программ, но и расширений для браузера.
1. Расширение для браузера Yandex Wordstat Assistant. Устанавливаете его в браузер, и при работе с Яндекс.Вордстат слева появится панель, в которую вы сможете собрать понравившиеся ключевые слова.

2. Key Collector – программа платная, но высокофункциональная.
- В настройках есть вкладка «Yandex.Wordstat». Перейдя на нее, Вы сможете установить глубину парсинга. Так можно собрать большее число ключей. Но рекомендуется ставить 0, чтобы не увеличивать время. А ключи можно расширить и другим способом, а времени на их собирание уйдет меньше. Максимальное количество страниц для парсинга в Yandex.Wordstat равно 40. На каждой странице при этом находится до 50 фраз. Таким образом, максимальное количество результатов по одной фразе в Вордстат – 2000. И если Вы хотите собрать больше данных, Вам нужно расширить входной список слов, добавив уточняющие слова. Например, не просто «капуста», а «цветная капуста», «производство капусты» и т.д.;
Яндекс Вордстат – это сервис компании Яндекс, используемый для подбора ключевых слов путем анализа поисковых запросов пользователей.
Зачем нужен Вордстат
В основном он применяется для составления семантического ядра. Wordstat бесплатен, он является многофункциональным инструментом, но настолько простым, что разобраться сможет даже новичок. С помощью Вордстата возможно узнать подробную статистику запросов в системе Яндекс за последний месяц, и составить не только структуру целого сайта, но и отдельных его страниц. В практике сервис применяется для решения следующих проблем:
- Сбор наиболее полной семантики за счет расширений запросов;
- Проверка частотности запросов, в том числе и региональной;
- Проверка сезонности запросов.
Это самое основное, но есть конечно и более мелкие задачи, которые помогает решить Wordstat.
Как правильно пользоваться Вордстатом
Сначала там нужно зарегистрироваться. Вот ссылка на сервис , вы можете и без регистрации вводить в нем слова, но вот результаты узнавать сможете только после регистрации. Иначе будет всплывать такая херня:
Также важно, чтобы в вашем профиле в Яндексе был указан ваш регион, по которому вы и собираетесь смотреть статистику запроса. Иначе, если вы будете искать, сколько клиентов для вашего бизнеса вводят в ваших Нижних Васюках слово «удочки», а у вас стоит регион Москва, то вам может выдать, что сотни тысяч людей ищут удочки. Вы накупите их сотню тысяч, а в Нижних Васюках их ищут всего-то пара калек.
После того, как зарегаетесь, вводите там слово и жмите кнопку «Подобрать». Вы получите такие результаты:

Как видите, мы ввели слово «браток», и в левой колонке будут запросы, в которых присутствует фраза «браток». Эти запросы вводят реальные пользователи. В правой колонке — похожие запросы. Цифры рядом с каждым запросом — это их частотность (то есть насколько часто пользователи их вводят). Но это не точная частотность, а приблизительная. То есть саму фразу «браток» именно в такой форме может вводили раз 20 всего (то есть точная частотность у нее 20 тогда), но вместе с фразами «братки», «братки 90», «давай браток» и другими у нее частотность 27 080. Точную же частотность мы научимся определять далее.
В основном с Вордстатом работают через специальные сервисы и программы. Тысячи их! Самая известная — Кей Коллектор. Все эти программы повышают удобство работы с этим инструментом в разы.
Напрямую с вордстатом работают очень редко, однако я слышал офигенные истории, что в студии Ашманова, одной из самых крутых SEO-студий, сидят мартышки, которые каждый запрос вводят в Вордстат руками и копируют выдачу в.txt-файл. Я сразу представил сотню рабов, которые за день работы выполняют такой же объем, как один сеошник с Кей Коллектором.
Давайте теперь смотреть остальные функции интерфейса:
В блоке 1
— переключение между типом устройств. Я лично не использую. Я свои сайты делаю удобными для всех типов устройств.
В блоке 2
— очень полезный переключатель. С его помощью можно посмотреть, во-первых, региональность запроса (в каком регионе его вводят чаще, в каком — реже). Можно серьезно залипнуть на этом инструменте. А во-вторых, тут можно посмотреть «Историю запроса» — и это действительно иногда очень нужно бывает для определения сезонности запроса и для отслеживания тренда.
В блоке 3
— дата, когда последний раз Яндекс обновлял статистику по запросам. В большинстве случаев нам это не нужно.
В блоке 4
— выбираем регион/регионы.
По регионам
Можно посмотреть, что где ищут. Забавная штука. Тут, например, можно выяснить, что блатные песни в среднем на душу населения больше всего ищут вовсе на в РФ, а в Греции и таки в Израиле:

А если вы нажмете на Россию, то увидите, что блатняк востребован в общем-то везде, но особенно — в Дагестане:

История запроса
В истории запроса можно определять сезонные запросы и тренды, как я уже говорил. Например, мы можем лишь завидовать тем вебмастерам, кто успел написать статьи про Трампа, потому что сейчас (конец 2016) у них начался рост трафика:

Но самое профессиональное начинается, когда вы работаете с операторами.
Какие операторы полезны при работе с Wordstat
Надо знать, как пользоваться операторами Яндекс Вордстата, чтобы наиболее эффективно работать в интерфейсе.
Базовые операторы
Два базовых оператора — восклицательное слово и кавычки. Это азы азов.
Смотрите, без них у нас 25 655 показов. Это показы всех фраз со словом «браток».
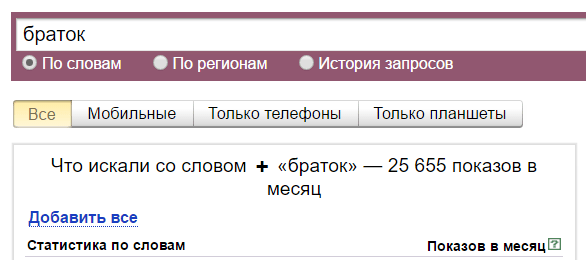
С кавычками же всего 832. Кавычки фиксируют фразу. Это значит, что 832 показа — у фраз «браток», «братка», «братку», вместе взятых, то есть у этой фразы с разным порядком слов и окончаниями, но без добавления к этой фразе других слов. То есть сюда не включаются показы фраз «мы братки», «завалили братка» и так далее.

С восклицательным знаком — 7409 показов. Он фиксирует словоформу. То есть сюда включаются показы фраз «браток», «ништяк браток», «держись браток» и других с таким же окончанием. А показы фраз «позвонить братку», «скачать песню про братка» и так далее — не включаются.

А тут мы имеем всего 152 показа. Это потому, что с восклицательным знаком и кавычками учитываются показы только этой фразы и только в этой форме. Но с разным порядком слов в фразе. То есть если мы введем «ништяк браток», то Вордстат нам покажет сумму показов «ништяк браток» и «браток ништяк».

Вспомогательные операторы
Плюс. Символ «+» принудительно учитывает стоп-слова. По умолчанию Вордстат не учитывает предлоги, и по запросу «как купить телевизор» покажет вам в основном коммерческие запросы:
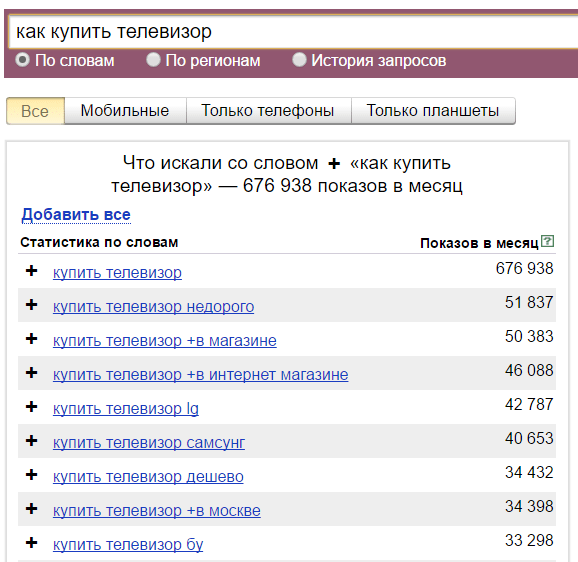
Если вам важна частица «как», то зафиксируйте её плюсом и Wordstat даст уже такие данные:

Оператор «ИЛИ». Прямой слэш «|» — если две фразы разделить этим оператором, он покажет все вариации с этими двумя фразами.

Он кстати позволяет провести сравнение двух запросов, для этого я его в основном и использую.
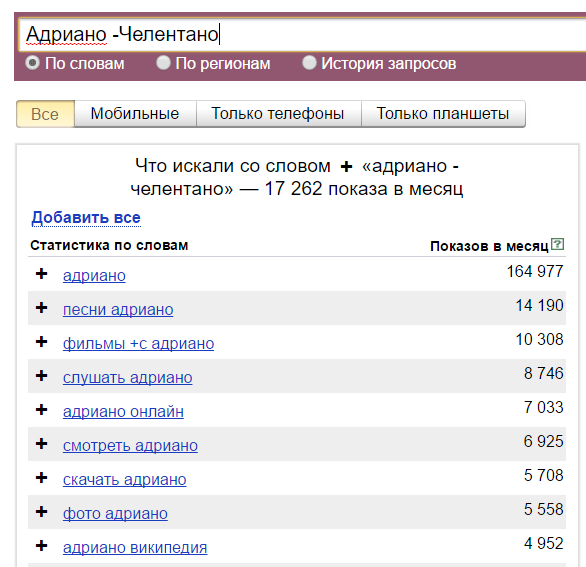
Минус. Символ «-» исключает конкретное слово из запроса. Пример: «купить машину в Москве -бу». Будут показаны запросы без употребления слова «бу».
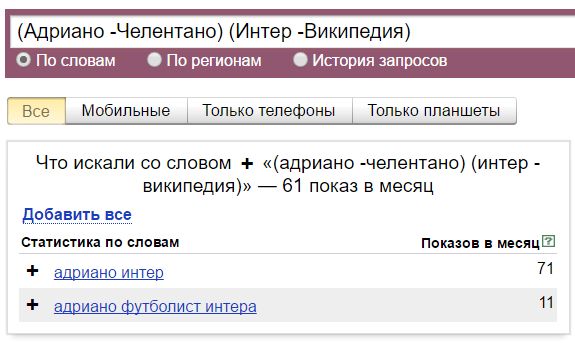
Круглые скобки «()» — группирует использование нескольких операторов.
Квадратные скобки «» — фиксирует последовательность слов в поисковой фразе. Этот оператор ввели не так давно. То есть мы получаем возможность узнать, с каким порядком слов фразу вводят чаще всего:

Как видим, с неправильным порядком фразу почти никто не вводит:

Плагины
Работать с голым Яндекс Wordstat в целом неудобно. Чтобы облегчить свой труд, можно установить себе в браузер специальный плагин, предназначенный для работы в Wordstat. Плагины для браузеров Хромиума (Яндекса, Мейла, Амиго, Оперы и Гугл Хрома) одинаковые, а вот для Мозилы идет отдельный плагин, все являются бесплатными и доступными для скачивания, устанавливать их можно сразу из браузера. Наиболее популярные — плагины Wordstat Assistant и Yandex Wordstat Helper.
Yandex Wordstat Assistant
Пожалуй, самый лучший плагин для wordstat.yandex.ru. Я сам им пользуюсь. Он удобен в использовании, практичен и не мешает, когда вы работаете на других сайтах. Установленный wordstat assistant запускается только в случае перехода на страницу Вордстата. Путем нажатия на плюсики, требуемое ключевое слово можно добавить в список (он находится слева). В ассистант есть возможность отсортировать выбранные ключевики, а ненужные удалить. Получившийся список просто скопируйте в буфер обмена, и перенесите в Excel для последующей обработки. Кстати, удобность использования плагина еще и в том, что когда вы добавляете в список уже находящиеся там фразы, дубли автоматически удаляются, что существенно сокращает работу.
Yandex Wordstat Helper
Этот плагин попроще, чем предыдущий, но не менее популярен, его также можно устанавливать прямо с браузера. Хелпер сделан в виде виджета, который добавляется на страницу вордстата сразу после установки, нужно просто обновить страницу и можно начинать работу. Его функции:
- Возможность автоматической сортировки в алфавитном порядке;
- Проверяет наличие дублей, удаляя последние;
- Есть возможность обработки разных запросов в нескольких вкладках браузера. Нужные слова добавляются в один и тот же список;
- Есть счетчик слов;
- Возможность копирования уже готового списка в Excel, собрав всё воедино по начальным фразам.
Прежде чем решить, какой плагин использовать, попробуйте в действии и тот и другой, это позволит вам сделать правильный выбор.
Парсеры Вордстата
Для экономии времени при подборе ключевых слов часто пользуются специально предназначенными для этого автоматическими программами – парсерами, которые могут быть как платными, так и бесплатными.
Некоторые пацаны заказывают парсеры и чисто под свои нужды.
Лучший платный парсер Wordstat – KeyCollector. Используют его в основном те, кто профессионально занимается составлением семантики. Бесплатным аналогом КейКоллектора является программа Словоеб. Функции его урезаны, но составлять небольшие ядра с его помощью вполне реально.
Магадан тоже достаточно популярный парсер Вордстат, который тоже можно бесплатно скачать. Подбирает и анализирует запросы, есть поддержка регионов, предназначен для парсинга фраз Яндекс Директа.
Под конец хочу отметить, что Вордстат дает только те данные, которыми располагает Яндекс. Поэтому например частотность в Гугле и других поисковиках может быть совсем другая.
Узнать частотности Wordstat можно вручную, но это долго и неудобно. Для ускорения работы есть парсеры: десктопные программы, расширения для браузеров, облачные сервисы и скрипты. Все они похожи - есть лишь отличия в нюансах работы. Собственный появился и в системе PromoPult. Разбираемся, как он работает и чем он лучше аналогов.
Основные возможности Парсера Wordstat в PromoPult:
- массовая проверка частотностей из левой колонки Wordstat для указанных фраз;
- загрузка фраз списком или с помощью файла XLSX;
- возможность парсить частотность в любом регионе Яндекса;
- учет типа соответствия при парсинге (операторы «фраза «, «!фраза » и [фраза ]);
- сохранение всех отчетов «в облаке».
Особенности сервиса:
- неограниченное количество поисковых запросов при проверке за один раз;
- сбор частотностей онлайн - не нужно устанавливать софт;
- не нужно создавать фейковые аккаунты в Яндексе специально для парсинга или рисковать собственными аккаунтами;
- не нужно использовать прокси-серверы и вводить капчу;
- суммирование в отчете частотностей по указанным регионам или разбивка по каждому региону;
- высокая скорость парсинга;
- удобный для последующей обработки отчет в формате XLSX.
Немного теории: зачем знать частотности ключевиков?
Основная причина, по которой собирают частотности, - прогнозирование трафика . Зная, сколько раз пользователи интересовались определенной фразой, можно примерно рассчитать, сколько сайт получит переходов, если займет N-ую позицию в поиске.
Как это работает на практике:
- вы сформировали список ключевых фраз, по которым планируете продвигаться;
- для фразы, по которой планируете оценить трафик, определяете частотность (например, «купить тахту в Москве » - 2852);
- узнаете значения CTR в зависимости от позиции в поиске (приблизительные данные о распределении CTR можно найти в открытых источниках, но если у вас сайт работает хотя бы несколько месяцев, то более точные данные доступны в отчете «Поисковые запросы» / «История запросов» / показатель: «CTR на позициях, %»);
- составляете прогноз трафика для ТОП-10 (для этого умножаете частотность на CTR и делите на 100 %; допустим, если CTR 2-3 позиции составляет 25 %, то прогнозный трафик при достижении этой позиции равен: 2852*25/100 = 713).
Вторая причина собирать частотности - отсеивание «мусорных» фраз . Это фразы, частотность которых стремится к нулю, и их нет смысла включать на существующие страницы (и тем более создавать под них новые страницы).
Какие именно фразы считать «мусорными» ? Здесь все зависит от тематики. Например, если тематика узкая, трафика мало (например, по ключам «покупка аппарата МРТ » или «ремонт Vertu »), и каждый пользователь на вес золота, то можно оставлять и фразы с частотностью 1. Для магазинов масс-маркета отсеивают запросы с частотностью ниже 5. А для информационных сайтов частотность 10-20 вполне может быть нижним пределом. Главное, не переусердствуйте с удалением лишних фраз, иначе есть риск потерять трафик по низкочастотным запросам, который порой составляет до 70-80 % от общего трафика.
Еще одна причина уточнить частотности - выстраивание иерархии запросов на странице . Более частотные запросы добавляют в Title и H1, а под менее частотные - формируют разделы и подразделы.
Продвигать сайт на автомате? С модулем SEO от PromoPult это реально! Внутренняя оптимизация, линкбилдинг, наполнение контентом - все это автоматизируется в пару кликов. Вам лишь остается контролировать результат. Готовы? !
Рассказываем, как собирать статистику запросов Яндекса с помощью парсера Wordstat, для чего эта статистика нужна и что такое «Яндекс.Wordstat». В каких случаях стандартный инструмент Яндекса не подходит и без автоматизации не обойтись. Как использовать парсер Wordstat от Click.ru.
О статистике запросов Яндекса и Вордстате
«Подбор слов» (wordstat.yandex.ru) – бесплатный сервис статистики поисковых запросов в Яндексе. Он показывает, как часто пользователи ищут в поиске то или иное слово или фразу.
С этим инструментом знакомится каждый, кто только начинает изучать продвижение в интернете: поисковую оптимизацию (SEO), контекстную рекламу (в Директе), контент-маркетинг.
Сама статистика поисковых запросов (ключевых слов, фраз или просто ключей) нужна предпринимателям, маркетологам и другим диджитал-специалистам для:
- Поискового продвижения действующего сайта: сервис помогает прогнозировать трафик из поиска Яндекса, оптимизировать имеющиеся страницы, разрабатывать новые разделы.
- Настройки и ведения контекстной рекламы:Вордстат позволяет понять, по каким словам и фразам размещать рекламу в Директе, а какие запросы нет смысла использовать.
- Запуска нового сайта: данные Яндекса стоит учитывать при планировании структуры будущего ресурса, а также закладке бюджета на контент, дизайн, рекламу.
- Анализа рынка перед запуском нового проекта: статистика поисковых запросов отражает интересы и потребности пользователей, спрос на товары и услуги с учетом географии и сезонности.
Зачем нужен специальный парсер Wordstat
Стандартный бесплатный инструмент Яндекса не предусматривает автоматизации. Подобрать ключевые слова и узнать статистику запросов в Вордстате можно только вручную. Вручную – значит долго и трудозатратно. И бессмысленно при большом объеме работы.
Конечно, функциональности Wordstat должно хватить, если нужно написать небольшую статью в блог или, например, настроить пару объявлений на один товар. Но что, если:
- Требуется проверить сотни, тысячи и десятки тысяч запросов? Это нормальная ситуация при работе с интернет-магазинами, сайтами сложных услуг, информационными порталами.
- У бизнеса широкая география, то есть необходимо узнавать частотность ключевых слов по каждому региону?
- Тематика предусматривает множество вложенных, двусмысленных, нерелевантных запросов? Так, например, слово «игрушки» может означать и мягкие, и елочные, и компьютерные игрушки. И игрушки для взрослых.
- Сроки поджимают – нужно запускать, продвигать, дорабатывать сайт в самое ближайшее время, а лучше уже вчера?
В таких случаях единственное решение – парсер Wordstat.
Как пользоваться парсером Wordstat от Click.ru
В числе инструментов Click.ru как раз есть функциональный и недорогой парсер Wordstat. Он быстро выдает частотность даже по большому списку запросов. При этом учитывает типы соответствия и региональность. Еще не требует капчу и прокси-серверы, а отчеты позволяет выгружать в Excel и хранить в «облаке».
Для начала работы зарегистрируйтесь в системе . После входа в свой аккаунт на главной странице выберите раздел «Парсер частоты Wordstat» и приступайте к работе.
 Для начала парсинга перейдите в соответствующий раздел
Для начала парсинга перейдите в соответствующий раздел
Как работать с парсером Wordstat после регистрации в Click.ru:
Загрузите список запросов.
Есть два способа: скопировать и вставить ключи в специальное поле или же загрузить XLSX-файл с ними.
При копировании списка учитывайте, что каждый ключ должен идти с новой строки. А в эксель-файле смотрите, чтобы не было вспомогательной информации (названий столбцов, лишних цифр и т. д.). Система берет запросы из первого листа.XLSX по принципу «одна ячейка – один ключ».
 Этап загрузки запросов
Этап загрузки запросов
Выберите регионы.
В системе доступны все регионы Яндекса. Можно посчитать общую частотность по нескольким регионам или получить статистику отдельно по каждому.
Разделять регионы в отчете нужно, если вы планируете продвигать бизнес отдельными региональными поддоменами и посадочными страницами, привязанными к географии. В остальных случаях галочка не ставится.
 Выбираем регионы
Выбираем регионы
Укажите тип соответствия.
Широкое соответствие – когда фразы пробиваются как есть – часто показывает обманчивую частотность. Все из-за того, что учитываются все вложенные ключи, в том числе нерелевантные (как в примере с игрушками). То есть всегда лучше перепроверять частоту запроса с помощью специальных операторов.
Кавычки позволяют уточнять статистику по конкретной фразе, без учета вложенных ключей.
Кавычки с восклицательными знаками показывают частотность по заданным словоформам.
Квадратные скобки – фиксируют порядок слов, что особенно важно в туристическом бизнесе
 Все варианты типов соответствия
Все варианты типов соответствия
Запустите проверку.
Время сбора частотностей зависит от количества запросов, регионов и типов соответствия. Если запросов меньше 1 000, процесс займет 1–2 минуты.
Результат будет доступен в списке задач. Можно открыть отчет в браузере или скачать его в формате XLSX.
 Здесь будут появляться отчеты со статистикой
Здесь будут появляться отчеты со статистикой
Сколько стоит парсинг Вордстата
Cтоимость парсинга в Click.ru в 3–5 раз ниже, чем у конкурентов. Особенно если нужна проверка большого пула поисковых запросов, например, для e-commerce.
Для тарификации в парсере используется базовая единица – ТЗ. Один ТЗ равен получению статистики одного ключа по одной группе регионов. Так, если разделить частотность по регионам, стоимость парсинга будет расти пропорционально числу регионов.