Дублированный контент – самая распространенная ошибка внутренней оптимизации. Внутренний враг — дубли страниц Как найти дубли
Дубль страницы - это еще одна копия страницы сайта, аналогичная по содержанию и наполнению. Выделяют два вида дублей:
- Полный дубликат страницы - когда содержимое полностью идентично;
- Частичный дубликат - когда наполнение страницы по большей степени одинаковое, но имеются отдельные различные элементы.
Почему дубли страниц плохо влияют на ранжирование сайта?
Поисковые системы воспринимают эти страницы, как отдельные страницы сайта, поэтому их наполнение из-за дублирования информации перестает быть уникальным. Кроме того, понижается ссылочный вес страницы, если она имеет дубль. Небольшое количество дублированных страниц может не стать большой проблемой, однако если их более 50% - вам срочно нужно исправлять ситуацию.
Откуда берутся дубли?
Самая распространенная причина - это генерация дублей страниц системой управления из-за неправильных настроек. Самый известный пример - CMS Joomla, с проблемой дублей на ней приходится сталкиваться чуть ли не на каждом сайте.
Частичные дубли часто встречаются на сайтах интернет-магазинов:
- Они могут появляться на страницах пагинации, если те содержат одинаковый текст, изменяя лишь товары;
- Неправильные настройки фильтра по каталогу могут порождать частичные и полные дубли;
- Страницы карточек товаров могут стать дубликатами, если товар, к примеру, отличается лишь цветом или размером (для таких товаров нужно делать одну карточку с указанием всех характеристик).
Как найти дубли страниц?
Есть несколько способов поиска дубликатов страниц, каждый из которых может дать разные результаты.
1. Некоторые распространенные варианты дублей можно проверить вручную.
- Настроено ли главное зеркало сайта (доступен ли он с www и без www);
- Имеются ли нечеткие дубли со / и без / на конце url;
- Наличие дублей с index.html, index.asp, index.php в конце url;
- Доступность страницы с буквами как в нижнем, так и в верхнем регистре, также порождает дубли.
2. Проанализировать страницы, проиндексированные поисковыми системами.
Для этого в Google достаточно ввести запрос site:mysite.com - он покажет страницы общего индекса, то есть все, что поисковик успел проиндексировать на сайте.

3. Поиск по фрагменту текста
Вбивая в поиск длинные фрагменты текста, можно найти места, где он повторяется (а заодно и сайты, которые скопировали ваш текст). Но здесь есть два минуса: метод подходит, если на сайте мало страниц, и то, что поисковая система может анализировать запрос до определенной длины.

4. Заглянуть в панель вебмастера Google
В разделе «Вид в поиске» находим вкладку «оптимизация HTML» и ищем значение поля «Повторяющиеся метаописания» и «Повторяющиеся заголовки». Нажав на них, можно увидеть список всех страниц с повторяющимися тегами title и description и сами заголовки и описания.

5. Воспользоваться программой Xenu`s Link Sleuth
Программа распространяется бесплатно и способна определить url всех страниц сайта, включая скрипты и картинки, а также внешние ссылки. Кроме дубликатов в ней удобно искать битые ссылки - страницы, которые возвращают код 404.

Как устранить дубли страниц?
Для этого существует 4 действенных способа, самыми жесткими из которых. По нашему мнению, являются первые два.
1. Ручное удаление
Это можно сделать на небольших сайтах, хорошенько разобравшись в своей системе управления и сделав правильные настройки, чтобы предотвратить последующее появление дубликатов страниц.
2. Настройка 301 редиректа
301 редирект - это постоянное перенаправление пользователей с одной страницы на другую, что приводит к их склеиванию. Он позволяет передать странице до 99% ссылочного веса, как внутреннего, так и внешнего.
По поводу использования 301 редиректа написаны целые мануалы. Поэтому здесь мы вкратце приведем самые нужные для устранения дублей. Настраивается он либо через файл.htaccess в корневой директории сайта, либо через программный код.
Чтобы настроить главное зеркало, необходимо прописать следующий код:
1 - для редиректа с www на без www
Чтобы склеить нечеткие дубли со / и без него, воспользуйтесь кодом:
1 - убрать слэш
Постраничный редирект выглядит так:
| Redirect 301 /oldpage.html http://www.site.com/newpage.html |
Для формирования более сложных редиректов потребуется воспользоваться правилами. Существуют специальные сервисы, где можно сгенерировать код для настройки редиректа по определенному шаблону:
3. Использовать Rel=”Canonical”
Этот вариант лучше использовать в случае частичных дублей, так как неканоническая страница при этом не удаляется физически с сайта и доступна пользователям.
Для того, чтобы настроить канонические url , в коде страниц в блоке head прописывается ссылка:
«link rel="canonical" href="http://site.com/kopiya"/»
4. Настройка Robots.txt
Также действенный способ, но удалить уже проиндексированные дубликаты таким образом будет сложно.
С помощью директивы Disallow указываются все адреса и их типы, на которые роботам поисковых систем не стоит заходить для индексации. Например:
User-agent: Yandex
Disallow: /index*
Говорит о том, что поисковому боту Яндекс не стоит заходить на страницы, url которых содержит index.
Найти и устранить все дубликаты - основная задача на первых этапах продвижения сайта, иначе можно взяться просто не за те страницы, и долго искать проблему.
— , который работает над продвижением сайта. Он может создать две одинаковые главные страницы, которые отличаются адресами.
Алгоритмы поисковых систем работают автоматически, и нередко бывает так, что дубль воспринимается системой более релевантным, чем страница-оригинал. В результате выдача будет выдавать не оригинал, а его дубль. В свою очередь, дубль обладает другими параметрами, что позже скажется на пессимизации сайта.
Существуют различные способы поиска и проверки дублированных страниц. От исполнителя они требуют разной степени знаний CMS, а также понимания того, каким образом работает поисковый индекс. Попробуем показать Вам наипростейший способ для проверки сайта на дубли страниц. Сразу отметим, что данный способ является не очень то и точным. Но, в тоже время подобный способ позволяет совершать поиск дублей страниц сайта, и не занимает много времени.
Теперь давайте посмотрим, как сделать то же самое только в системе Google. В принципе, процедура ничем не отличается, потребуется совершить такие же действия, как и в Яндексе.
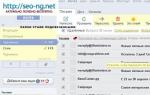
Поисковая система Яндекс сразу же предоставляет список дублей, а вот в Гугле, чтобы увидеть дубли, необходимо будет дополнительно нажать «Показать скрытые результаты», поскольку зачастую на экран выводится оригинал страницы.
С картинки видно что, в основной выдаче находится 1 страница сайта, и она же и является оригиналом. Но в индексе существуют другие страницы, являющиеся дублями. Чтобы их увидеть, нужно нажать на ссылку “Показать скрытые результаты”. В результате мы получаем список, где под номером 1 находится оригинал, а дальше уже размещены дубликаторы. Частенько дубли придется чистить вручную.
Как проверить сайт на дубли страниц
В ниже приведенной статье мы сегодня попытаемся рассмотреть много вопросов, касающихся проблемы дублирования страниц, что становится причиной возникновения дублей, как от этого избавиться, и вообще, почему нужно избавляться от дубликатов.
Для начала давайте разберемся, что кроется под понятием «дублирование контента». Нередко случается, что некоторые страницы могут содержать частично или в полной мере одинаковый контент. Понятно, что каждая отдельная страница имеет свой собственный адрес.
Причины возникновения дублей:
— владельцы сайта сами создают дубли для определенных целей. Допустим, это может быть страница для печати, которая позволяет посетителю коммерческого сайта скопировать необходимую информацию по определенному товару или услуге.
— они генерируются движком интернет-ресурса, поскольку это заложено в их теле. Определенное количество современных СMS могут выдавать похожие страницы с различными URL, которые размещены на разных директориях.
— ошибки вебмастера, который работает над продвижением сайта. Он может создать две одинаковые главные страницы, которые отличаются адресами.
— изменение структуры сайта. При создании нового шаблона с иной системой URL, новые страницы, вмещающие старый контент, получают другие адреса.
Мы перечислили возможные причины возникновения четких дублей, но существуют еще и нечеткие, то есть частичные. Зачастую подобные страницы имеют схожую часть шаблона ресурса, но контент их немного отличается. Подобными дублями могут быть страницы сайта, которые имеют одинаковый результат поиска или же отдельный элемент статьи. Чаще всего, такими элементами становятся картинки.
От дублированных страниц необходимо избавляться. Нет, это не вирус, но он также со временем разрастается, правда, это зависит не от самого ресурса. Дубли зачастую становятся последствием непрофессионального вебмастера, или же результатом неправильного кода сайта.
Важно знать, что дубли могут нанести ресурсу немалый ущерб. К каким же последствиям может привести наличие дублей на сайте? Во-первых, это ухудшение индексации ресурса. Согласитесь, что подобная ситуация не очень то обрадует владельца сайта. В то время как на продвижение ресурса постоянно тратятся финансы и время, ресурс начинает терять свою популярность за несколько дней. Глубина проблемы будет зависеть от количества дублей.
Бывает так, что главная страница может иметь пару-тройку дубликатов. С блогам дело обстоит несколько по-другому. Благодаря replytocom может быть огромное количество дублей из-за копирования комментариев. Получается, что чем популярнее блог, тем больше дубликатов он будет содержать. В свою очередь, системы поиска, в особенности Google, из-за наличия таких вот дублей занижает позиции ресурса.
Алгоритмы поисковых систем работают автоматически, и нередко бывает так, что дубль воспринимается системой более релевантным, чем страница-оригинал. В результате выдача будет выдавать не оригинал, а его дубль. В свою очередь, дубль обладает другими параметрами, что позже скажется на пессимизации сайта.
Что же у нас получается? Дублированные страницы становятся реальной помехой в индексации сайта, а также причиной неверного выбора поисковой системы релевантной страницы, снижают влияние естественных ссылок. Помимо этого, дубли неправильно распределяют внутренний вес, снижая силу продвигаемых страниц, а также меняя поведенческие показатели.
Как проверить сайт на дубли страниц?
Существуют различные способы поиска и проверки дублировааных страниц. От исполнителя они требуют разной степени знаний CMS, а также понимания того, каким образом работает поисковый индекс. Попробуем показать Вам наипростейший способ для проверки сайта на дубли страниц. Сразу отметим, что данный способ является не очень то и точным. Но, в тоже время подобный способ позволяет совершать поиск дублей страниц сайта, и не занимает много времени.
Для поиска и проверки собственного ресурса на наличие дубликатов, следует просто ввести в расширенный поиск поисковой системы специальный запрос. Если Вы используете расширенную версию поиска в Яндекс, можно получить довольно подробные результаты благодаря тому, что здесь имеется возможность вводить уточняющие параметры для запроса.
Нам понадобится адрес ресурса и та часть текста, дубликат которого мы хотим найти. Для этого нам потребуется на своей странице выделить фрагмент текста, после чего в расширенном поиске системы Яндекс ввести скопированный текст и адрес сайта. Теперь необходимо нажать кнопку «Найти», после чего система начнет поиск.
Результаты будут выведены не в обычном режиме. Список сайтов будет содержать только заголовки и сннипеты нашего ресурса. В том случае, когда система выдает единственный результат, это значит, что дубликатов данной страницы нет. А вот при выдаче нескольких результатов придется поработать.
Теперь давайте посмотрим, как сделать то же самое только в системе Google. В принципе, процедура ничем не отличается, потребуется совершить такие же действия, как и в Яндексе.
Расширенный поиск позволяет легко находить все дубликаты по определенному фрагменту текста. Безусловно, что таким способом мы не получим дублей страниц, которые не содержат указанного текста. Нужно сказать что, если дубль был создан искривленным шаблоном, то он только показывает, например, картинку из оригинала на другой странице. Разумеется, что если текста дубликат не содержит, то выше описанным способом его определить не удастся. Для этого необходим другой способ.
Второй способ также отличается своей простотой. Надо воспользоваться специальным оператором и запросить индексацию своего сайта, или же его отдельных страниц. После этого придется вручную смотреть выдачу в поиске дублей.
Правила синтаксиса необходимого запроса:
В той ситуации, когда в поиск вводится просто адрес главной страницы, нам показан список проиндексированных страниц с помощью поискового робота. А вот, если укажем адрес конкретной страницы, то система выводит уже проиндексированные дубли данной страницы.
Поисковая система Яндекс сразу же предоставляет список дублей, а вот в Гугле, чтобы увидеть дубли, необходимо будет дополнительно нажать «Показать скрытые результаты», поскольку зачастую на экран выводится оригинал страницы.
Как видно на картинке, в основной выдаче у нас находится одна страница сайта и она же является оригиналом. Но в индексе есть и другие страницы, которые являются дублями. Чтобы их увидеть, нужно нажать на ссылку “Показать скрытые результаты”. В результате мы получаем список, где под номером 1 находится оригинал, а дальше уже размещены дубликаторы. Частенько дубли придется чистить вручную.
План статьи
Дубли страниц — страницы с одинаковым контентом, доступным по разным URL. Рассмотрим наиболее важные вопросы: как найти дубли страниц, чем вредны дубликаты страниц, частые причины дублирования, удаление дубликатов, примеры.
Чем вредны дубли страниц
Проблема дублей на сайте вызывает у поисковых систем ряд вопросов — какая страница является каноничной, какую страницу показывать в поисковой выдаче и является ли сайт, показывающий посетителям дубликаты страниц качественной площадкой.
Google борется с дубликатами страниц с помощью фильтра Panda, начиная с 2011 года. На данный момент фильтр является частью неотъемлемой частью формулы ранжирования. При наличии Панды, сайт теряет большую часть трафика из поисковой системы.
Яндекс в рекомендациях для вебмастеров рекомендует избегать дублей и предупреждает, что поисковая система выберет лишь одну страницу из дублирующихся в качестве канонической.
Частые причины дублирования страниц
Наиболее частой причиной дублирования страниц является особенность строения CMS, на которых разработан сайт. К примеру, в Joomla есть множество конструкций URL, по которым будет доступен один и тот же контент. Даже в последних версиях WordPress есть вариант доступности контента записей по конструкции site.ru/postID и site.ru/ЧПУ. А в магазинной CMS Opencart: при ЧПУ с включением названии категории — привязанность товара к разным категориям. Некоторые неопытные SEO-оптимизаторы берут за основу один контент и размножают его, меняя всего пару слов в тексте. По такому же принципу работают и дорвеи. Такое дублирование называется частичным и за такое дублирование на сайт также могут быть наложены санкции (Google Panda и др).
Вторая популярная версия дублирования — доступность страниц с www и без (www.site.ru и site.ru). При таком дублировании все версии сайта должны быть добавлены в Google Webmaster Tools, после чего уже избавляться от них.
Третья по популярности вариация дубликатов — наличие контента со слэшем в конце URL и без него.
Поиск и удаление дублей страниц на сайте входит в услугу . Экономьте, заказывая у индивидуального специалиста.
Сервисы и программы поиска
Наиболее быстрый и обычно, точный, способ — найти дубликаты страниц по Title и мета-тегам. Ниже — сервисы и программы, которыми пользуюсь сам.
Сервисы для поиска дублей по Title и мета-тегам:
- Инструмент «Аудит сайта» в сервисе Serpstat (комплексные сервисы для SEO, PPC ~$100/месяц).
- Аудит в сервисе Seotome (за 500 рублей — аудит 1 сайта).
- Другие, если знаете, пишите в комментариях.
Сервисы для поиска частичных дубликатов по контенту:
- Аудит в сервисе Seotome (за 500 рублей аудит 1 сайта). Показывает в процентном соотношении дублирование контента на страницах.
Программы для поиска дублей по Title и мета-тегам:
- Website Auditor от SEO Power Suite (Mac, Windows, Linux, ~$50/единоразово).
- Netpeak Spider (Windows only, $14/месяц).
- Comparser (Windows only, 2000 рублей).
- Xenu (Windows only, free).
Программы для поиска дублей по контенту:
Если знаете подобный софт — напишите в комментарии или по — добавлю в список.
Основные способы избавления от дублей страниц на сайте
- Использовать rel=»canonical», который указывает каноническую версию страницы. Лучший способ избавиться от дублей. При использовании canonical практика показала, что веса дублирующих страниц склеиваются, что хорошо для продвижения.
- Закрыть дублирующиеся страницы от индексации. Можно закрывать конструкциями в robots.txt (как пользоваться robots.txt) или наличием на странице мета-тега .
- Добавить 301 редирект с дублирующей страницы на основную. Подходит при дублировании www/без, слэш на конце/без. Настраивается в файле.htaccess или специальными плагинами.
Как найти дубли страниц: Примеры
Поиск дублей с помощью Serpstat
Поиск дублей с помощью Website Auditor

Поиск дублей с помощью Comparser

Поисковые алгоритмы постоянно развиваются, часто уже сами могут определить дубли страницы и не включать такие документы в основной поиск. Тем не менее, проводя экспертизы сайтов, мы постоянно сталкиваемся с тем, что в определении дублей алгоритмы еще далеки от совершенства. Вот что пишут о дублях представители Яндекса:
Я думаю, не стоит надеяться, что в вашем случае алгоритм оценит все страницы правильно и его выбор совпадет с вашим 😉 – лучше самому избавиться от дублей на сайте.
Почему нужно избавляться от дублей?
Предлагаю для начала рассмотреть, чем опасны дубли страниц.
Ухудшается индексация сайта
Если в вашем проекте несколько тысяч страниц, и на каждую из них создается по одному дублю, то объем сайта уже «раздувается» в два раза. А что, если создается не один дубль, а несколько? В прошлом году мы проводили экспертизу новостного портала, в котором каждая новость автоматически публиковалась в семи разделах, то есть каждая страница сразу создавалась еще с шестью дублями.
Неправильно распределяется внутренний ссылочный вес
Часто дубли на сайте появляются в результате неправильных внутренних ссылок. В итоге страницы-дубли могут считаться более значимыми, чем основная версия. Не стоит забывать и про пользовательские факторы. Если посетитель попал на дубль страницы, то, соответственно, измеряются ее показатели, а не оригинала.
Изменение релевантной страницы в поисковой выдаче
Поисковый алгоритм в любой момент может посчитать дубль более релевантным запросу. Смена страницы в поисковой выдаче часто сопровождается существенным понижением позиций.
Как найти дубли?
Теперь давайте рассмотрим, как можно найти внутренние дубли на сайте.
1. Анализ данных Google Webmasters
Пожалуй, самый простой из способов. Для того чтобы найти страницы дублей, вам будет достаточно зайти в панель инструментов, выбрать вкладку «Вид в поиске» и перейти по ссылке «Оптимизация html»:

Наша цель – это пункты:
— «Повторяющееся метаописание»
. Здесь отображены страницы с одинаковыми описаниями (description);
— «Повторяющиеся заголовки (теги title)»
. В этом пункте находится список страниц с одинаковыми заголовками (Title).
Дело в том, что на страницах обычно совпадает не только контент, но и мета-данные. Проанализировав список страниц, отображаемых в этих вкладках, легко можно выявить такие дубли. Мы рекомендуем периодически проверять вышеупомянутые вкладки панели инструментов на наличие новых ошибок.
Проверить страницы на совпадающие заголовки можно даже в том случае, если доступа к панели у вас нет. Для этого вам нужно будет воспользоваться расширенным поиском поисковой системы или сразу ввести в поисковую строку соответствующий запрос.
Для Яндекса:
site: сайт title:(анализ сайтов)
Для Google
:
site: сайт intitle:анализ сайтов
Разумеется, необходимо подставить свой домен и часть заголовка, дубль которого вы ищете.
2. Анализ проиндексированных документов
Анализ в первую очередь лучше проводить в той поисковой системе, в индексе которой находится больше всего страниц. В большинстве случаев это Google. С помощью оператора языка запросов «site» легко получить весь список проиндексированных страниц. Вводим в строку поиска:
site:сайт (не забудьте указать имя своего домена) и получаем список проиндексированных страниц.

Просматривая выдачу, обращайте внимание на нестандартные заголовки и url страниц.
Например, вы можете увидеть, что в выдаче попадаются страницы с идентификаторами на конце, в то время как на сайте настроены ЧПУ. Нередко уже беглый анализ проиндексированных страниц позволяет выявить дубли или другие ошибки.
Если на сайте большой объем страниц, то при анализе может помочь программа Xenu. Об использовании этого инструмента можно прочесть на блоге Сергея Кокшарова.
3. Поиск дублей по части текста
Два предыдущих способа помогают выявить дубли в тех случаях, когда на страницах совпадают мета-данные. Но могут быть и другие ситуации. Например, статья на сайте попадает сразу в несколько категорий, при этом в title и description автоматически добавляется название категории, что делает мета-данные формально уникальными. В этом случае ошибки в панели инструментов мы не увидим, а при ручном анализе сниппетов страниц такие дубли легко пропустить.
Для того чтобы выявить на сайте подобные страницы, лучше всего подойдет поиск по части текста.
Для этого нужно воспользоваться инструментом «расширенный поиск» и произвести поиск на сайте по части текста страницы. Текст вводим в кавычках, чтобы искать страницы с таким же порядком слов и формой, как в нашем запросе.
Так выглядит расширенный поиск в Яндексе:

А вот так в Google:
На сайтах может быть много сотен или даже тысяч страниц. Разумеется, не нужно анализировать все страницы. Их можно разбить по группам. Например, главная, категории, товарные карточки, новости, статьи. Достаточно будет проанализировать по 2-3 страницы каждого вида, чтобы выявить дубли или убедиться, что на сайте все в порядке.
Чистим сайт от дублей
После того как дубли обнаружены, можно приступать к их удалению.
Находим и устраняем причину появления дублей
Первое, что необходимо сделать – найти причину, из-за которой дубли на сайте появляются, и постараться ее устранить.
Причины могут быть различные, например:
- ошибки в логике структуры сайта;
- технические ошибки;
- различные фильтры и поиск по сайту.
В каждом случае ситуацию необходимо рассматривать индивидуально, но если дубли функционально не полезны, то от них лучше просто отказаться.
Указываем канонический адрес страницы
Если страницы-дубли по каким-то причинам нельзя удалить, то следует указать поисковым роботам, какая страница является основной (канонической). Google ввел для этого специальный атрибут rel=»canonical» (рекомендации по использованию атрибута).
Через некоторое время его стал поддерживать и Яндекс. И на сегодняшний день это основное официальное средство для борьбы с дублями страниц.
Использование 301 редиректа
До внедрения rel=»canonical» 301 редирект был основным способом склейки страниц-дублей. И сейчас разработчики и оптимизаторы продолжают активно использовать 301 редирект для переадресации на основное зеркало сайта или со страниц с «/» или без него на конце.
Запрет к индексации в robots.txt
В файле robots.txt мы можем запретить доступ к определенным разделам или типам страниц, например, страницам, формируемым в результате поиска по сайту. Но это не избавит нас от дублей страниц в Google. Дело в том, что доступ к страницам будет запрещен, но если страницы уже попали в индекс, они после добавления запрета исключены не будут.
Следует отметить, что даже если вы запретите поисковым роботам сканировать содержание вашего сайта с помощью файла robots.txt, возможно, что Google обнаружит его другими способами и добавит в индекс. Например, на ваш контент могут ссылаться другие сайты.
Для того чтобы страница была удалена из индекса, на нее необходимо добавить , но при этом важно, чтобы страница не была закрыта в robots.txt. Иначе поисковый робот на нее не зайдет.
Если ваша страница продолжает появляться в результатах, вероятно, мы еще не просканировали ваш сайт после добавления тега. (Кроме того, если вы заблокировали эту страницу с помощью файла robots.txt, мы также не сможем увидеть этот тег.)
В связи с этим, если дубли на сайте уже есть, robots.txt не поможет удалить их из индекса Google.
Остается пожелать оптимизаторам успехов в борьбе с дублями и развитии своих проектов.
Подписаться на рассылкуа если дубль по контенту, а урл другой, стоит каноникал и в робтсе закрыт, но страница в индексе, как это расценивать?
Каноникал решает проблему с дублированием.
Но если страница попала в индекс, а потом ее в robots.txt закрыли, то робот не может просканировать ее еще раз и пересчитать параметры.
Согласен с предыдущим ответом. Решить проблему можно послав запрос на удаление в поисковой консоли.
Maksim Gordienko
Почему для страниц пагинации рекомендуется использовать canonical, вместо удаления текста + noindex, follow + дописывание в начале Title конструкции "Страница N" на второй и последующих страницах пагинации (а можно еще и prev / next добавить)? Сталкивался с тем, что при размещении canonical товары со второй и последующих страниц плохо индексировались.
Была ли практика использования HTTP-заголовка X-Robots-Tag для запрета индексации страниц, так как при использовании robots часто всплывают такие страницы: http://my.jetscreenshot.com... ?
Каноникал - это всего лишь рекомендация. Еще можно использовать 301-редирект для релевантных страниц. По программам для поиска дублей - рекомендую Компарсер + показывает структуру сайта и еще несколько полезных фич есть. Серпстат - дорогой.
Используй лучше каноникал и прев-нектс и будет супер.
Maksim Gordienko
Сеопрофи, например, пишет что каноникал на пагинации имеет смысл ставить только если есть страница "показать все товары" (да и в рекомендациях Google не приводится пример с пагинацией в её классическом виде). А так, товары (содержимое) на второй странице отличается от первой, ставить каноникал нелогично.
Если нужно только дубли проверить, то лучше использовать специфический софт. Советую Netpeak Spider. Он сейчас активно развивается и проверяет очень много параметров на сайте https://netpeaksoftware.com... . Мы его постоянно используем в работе.
Serpstat хорош тем, что это платформа со множеством инструментов: аналитика запросов, ссылок, аудит, проверка позиций.
Підкажіть, буд ласка, ми видалили з сайту інтернет-магазину певні категорії, створили нові, в видалених категоріях були товари і ми цим товарам прописали нові категорії - після цього в нас створилися нові сторінки товарів вже де в урл нові категорії і утворилися дублі. Як краще зробити? Зробити урл товару статичним (а не динамічним) і з нових створених сторінок поставити 301 редиректи на старі? (інтернет-магазин існує 6 місяців) чи має змінюватися урл товару якщо змінили категорію? (в структурі урла товару є назва категорії).
1. Щоб уникнути дублювання URL товарів ми зазвичай поміщаємо їх в одну папку /product/, а категорії задаються в меню і хлібних крихтах.
2. Якщо нема можливості так зробити, то виберіть один із варіантів.
2.1. Використовуйте rel canonical на основную сторінку товару. Скоріше всього, в вашому випадку це нова сторінка, тому що нова категорія вказана в URL. Але ви самі вибирайте головну сторінку.
2.2. Використовуйте 301 редирект на головний URL. При цьому на сайті не повинно бути посилань на старі URL, тобто посилань на 301 редирект.
3. URL товарів краще робити статичными або User Friendly.
4. "чи має змінюватися урл товару якщо змінили категорію? (в структурі урла товару є назва категорії)."
Якщо нема можливості не задавати категорію в URL (як в п.1.), то при кожній зміні категорії в URL її теж треба міняти і налаштовувати 301 редирект на нову адресу.
Дякую за таке обширне пояснення)
Подскажите, как избежать дублей контента. Есть 33 позиции однотипного товара https://delivax.com.ua/pack...
Писать к каждому уникальное описание - сложно и вроде как не нужно. Но из-за того, что описание дублируется, из 33 позиций в индексе висит только 5. Стоит ли переживать по этому поводу и что с этим делать?